![[하네스 리뷰] Harness: Claude Code 에이전트 팀 플러그인 실험](/content/images/size/w1200/2026/03/hero.png)
도입
Claude Code를 쓰다 보면 한 세션에서 기획, 구현, 테스트를 전부 시키게 된다. 잘 될 때도 있다. 하지만 복잡한 작업에서는 뭔가 빠진다. 보안 리뷰를 시키면 성능은 놓치고, 조사 보고서를 시키면 한쪽으로 치우친다.
Harness라는 오픈소스 플러그인이 이걸 해결한다고 한다. "한 문장으로 전문 에이전트 팀을 자동 설계하고, 품질이 60% 올라간다"고.
진짜 그런지 직접 6가지 시나리오로 돌려봤다.
Harness가 하는 일
한 줄 요약
Claude Code에서 "이 프로젝트를 위한 harness를 구축해줘"라고 말하면, 프로젝트를 분석해서 .claude/agents/에 전문 에이전트 정의를, .claude/skills/에 각 에이전트가 쓸 스킬을 자동 생성하는 메타 스킬이다.
뭐가 다른가
Claude Code에 "코드 리뷰해줘"라고 하면, 보통은 한 명이 전부 한다. 보안도, 성능도, 접근성도, 구조도. 혼자서. 전부 깊이 보기는 어렵다.
Harness는 이걸 전문가 팀으로 쪼갠다:
기존 — 1인 다역
Claude 1명이 보안, 성능, 접근성, 아키텍처를 순서대로 훑는다. 넓고 얕다.
Harness — 전문가 팀
보안 전문가, 성능 전문가, 접근성 전문가, 아키텍처 전문가가 각자 독립적으로 깊이 파고든 후, 통합 리포터가 종합한다.
핵심은 "독립 컨텍스트"다. 보안 전문가는 보안만 생각한다. 성능 전문가가 옆에서 뭘 하는지 모른다. 서로 영향을 안 주니까, 같은 이슈를 다른 관점에서 독립적으로 발견할 수 있다.
작업마다 팀 구조가 다르다
팀으로 쪼갠다고 했는데, 쪼개는 방식이 하나가 아니다. 웹앱을 만들 때는 기획 → 구현 → 테스트 순서가 중요하고, 코드 리뷰를 할 때는 보안·성능·접근성 전문가가 동시에 보는 게 낫다.
이처럼 작업 성격에 따라 팀을 짜는 방식이 달라야 한다. Harness는 6가지 구조를 지원하는데, 이번 실험에서는 5가지를 사용했다:
| 패턴 | 구조 | 적합한 작업 | 실험 |
|---|---|---|---|
| Pipeline | A → B → C 순차 | 기획 → 구현 → 테스트 | 시나리오 1 |
| Fan-out/Fan-in | 병렬 수행 → 통합 | 코드 리뷰, 리서치 | 시나리오 2, 3 |
| Producer-Reviewer | 생성 → 검증 반복 | 코드 생성 + QA | 시나리오 4 |
| Expert Pool | 상황별 전문가 선택 | 에러 유형별 디버깅 | 시나리오 5 |
| Supervisor | 중앙에서 동적 분배 | 콘텐츠 제작 총괄 | 시나리오 6 |
| Hierarchical | 재귀적 위임 | 대규모 시스템 설계 | 미실험 |
Harness 팀이 발표한 수치
A/B 테스트(15개 소프트웨어 엔지니어링 작업):
- 평균 품질 점수: 49.5 → 79.3 (+60%)
- 출력 편차: 32% 감소
- 복잡한 작업일수록 개선 폭이 큼
인상적이다. 하지만 직접 해봐야 안다.
실험 설계
궁금한 것
- Harness가 진짜 더 나은 결과물을 만드는가?
- 어떤 유형의 작업에서 차이가 크고, 어디서 작은가?
- 추가 비용(토큰, 시간)을 감안하면 투자 대비 효과가 있는가?
- "자기 맹점(self-blindness)" — 한 세션이 자기가 만든 코드를 리뷰할 때 놓치는 것이 있는가?
6가지 시나리오
| # | 시나리오 | 패턴 | 왜 이 작업을? |
|---|---|---|---|
| 1 | 웹앱 개발 | Pipeline | 구현 능력 직접 비교 |
| 2 | 리서치 보고서 | Fan-out/Fan-in | 조사 깊이와 관점 다양성 |
| 3 | 코드 리뷰 | Fan-out/Fan-in | 전문성 깊이와 맹점 발견 |
| 4 | 유틸리티 라이브러리 | Producer-Reviewer | 생성-검증 분리의 효과 |
| 5 | 프로덕션 인시던트 진단 | Expert Pool | 전문가 선택 호출의 가치 |
| 6 | 콘텐츠 기획 | Supervisor | 중앙 조율의 효과 |
격리 방법
각 실험은 완전히 독립된 디렉토리에서 실행. Harness는 프로젝트 로컬(.claude/)에만 설치되므로 Vanilla 쪽에는 어떤 영향도 없다.
시나리오 1: 웹앱 개발 (Pipeline)
프롬프트: "할 일 관리 웹앱 — 카테고리별 분류, 드래그앤드롭, 다크/라이트 테마, localStorage, 반응형 UI. 단일 HTML."
구성된 하네스: Pipeline (순차 실행)
├── planner — 요구사항 분석, 기능 스펙, 데이터 모델 설계
├── builder — 스펙 기반 단일 HTML 구현
└── qa — 기능 검증, 엣지 케이스 테스트결과 비교
| 항목 | Vanilla | Harness |
|---|---|---|
| 코드 라인수 | 1,138줄 | 1,480줄 |
| 토큰 사용량 | 20,013 | 68,875 |
| 소요 시간 | 2.6분 | 7.1분 |
| 산출물 | app.html | app.html + spec.md + QA report |
실제 결과물
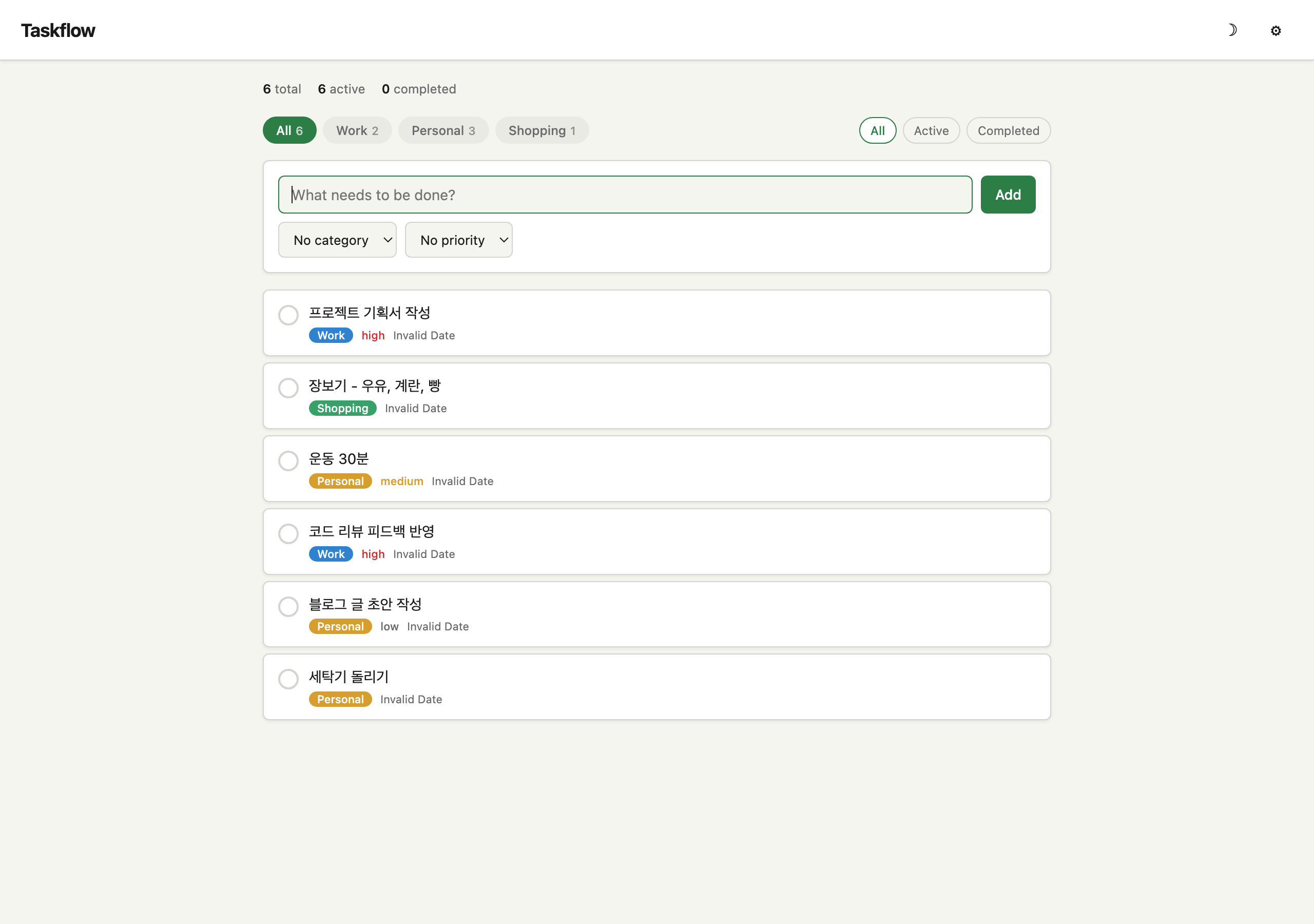
Vanilla
Harness
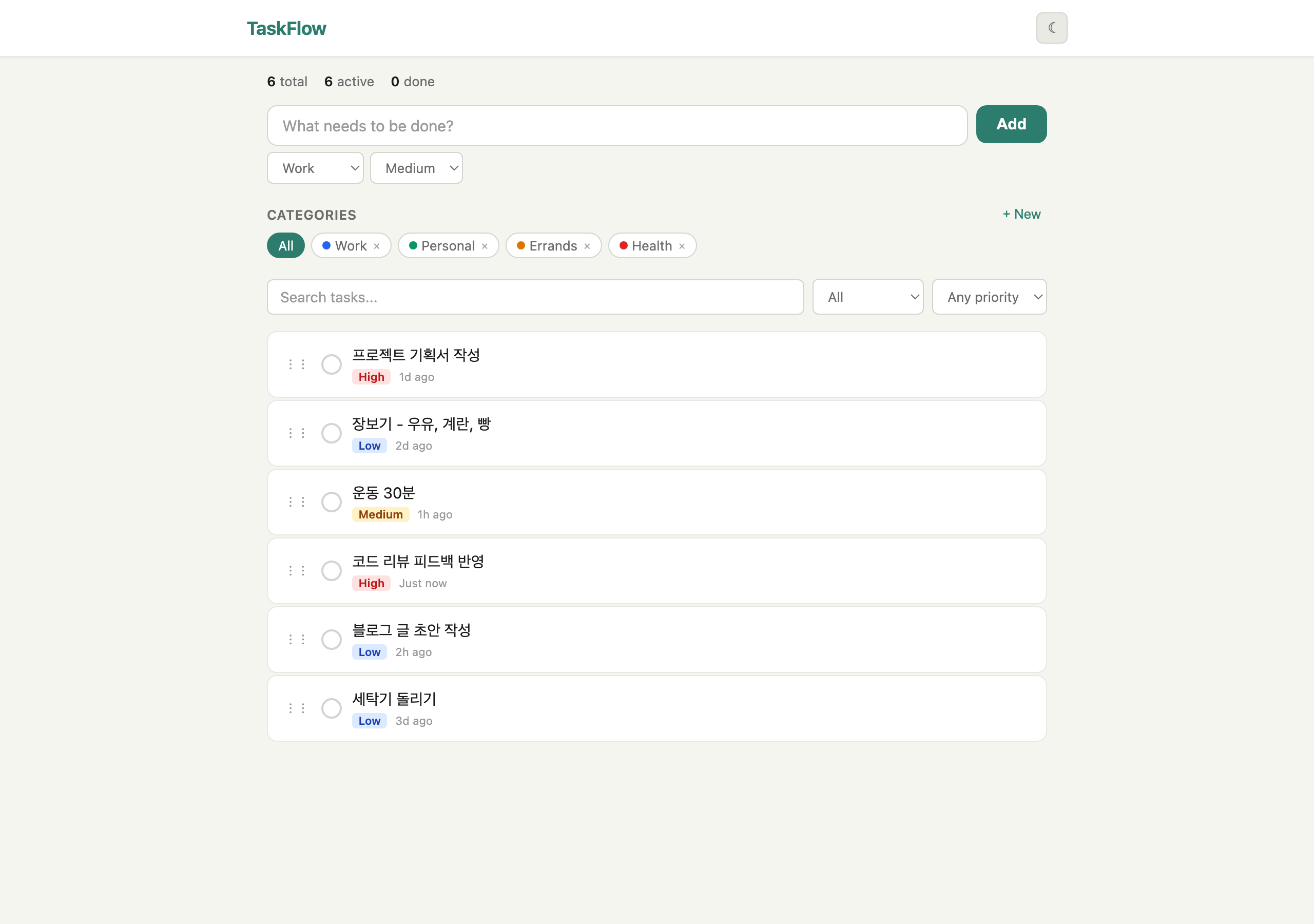
같은 할 일 6개를 넣고 비교했다. Vanilla는 카테고리 뱃지와 우선순위 텍스트를 보여주고, Harness는 검색 바, 색상 칩 카테고리 필터, 우선순위 필터 드롭다운, 상대 시간("1h ago") 등 UI 요소가 더 풍부하다.
시나리오 2: 리서치 보고서 (Fan-out/Fan-in)
프롬프트: "프론트엔드 프레임워크 비교 보고서 — React, Vue, Svelte, Solid, Angular. 성능, 생태계, 학습 곡선, 채용 시장, 커뮤니티 비교."
구성된 하네스: Fan-out/Fan-in (병렬 조사 → 통합)
├── react-specialist — React 생태계 전문 리서처
├── vue-specialist — Vue 생태계 전문 리서처
├── svelte-specialist — Svelte 생태계 전문 리서처
├── solid-specialist — SolidJS 생태계 전문 리서처
├── angular-specialist — Angular 생태계 전문 리서처
└── integrator — 5명의 조사 결과를 교차 비교 → 통합 보고서결과 비교
| 항목 | Vanilla | Harness |
|---|---|---|
| 보고서 길이 | 15,085자 / 383줄 | 16,957자 / 410줄 |
| 참고 소스 | 25개 | 30+개 |
| 토큰 사용량 | 40,851 | 92,233 |
실제 결과물: 보고서 비교
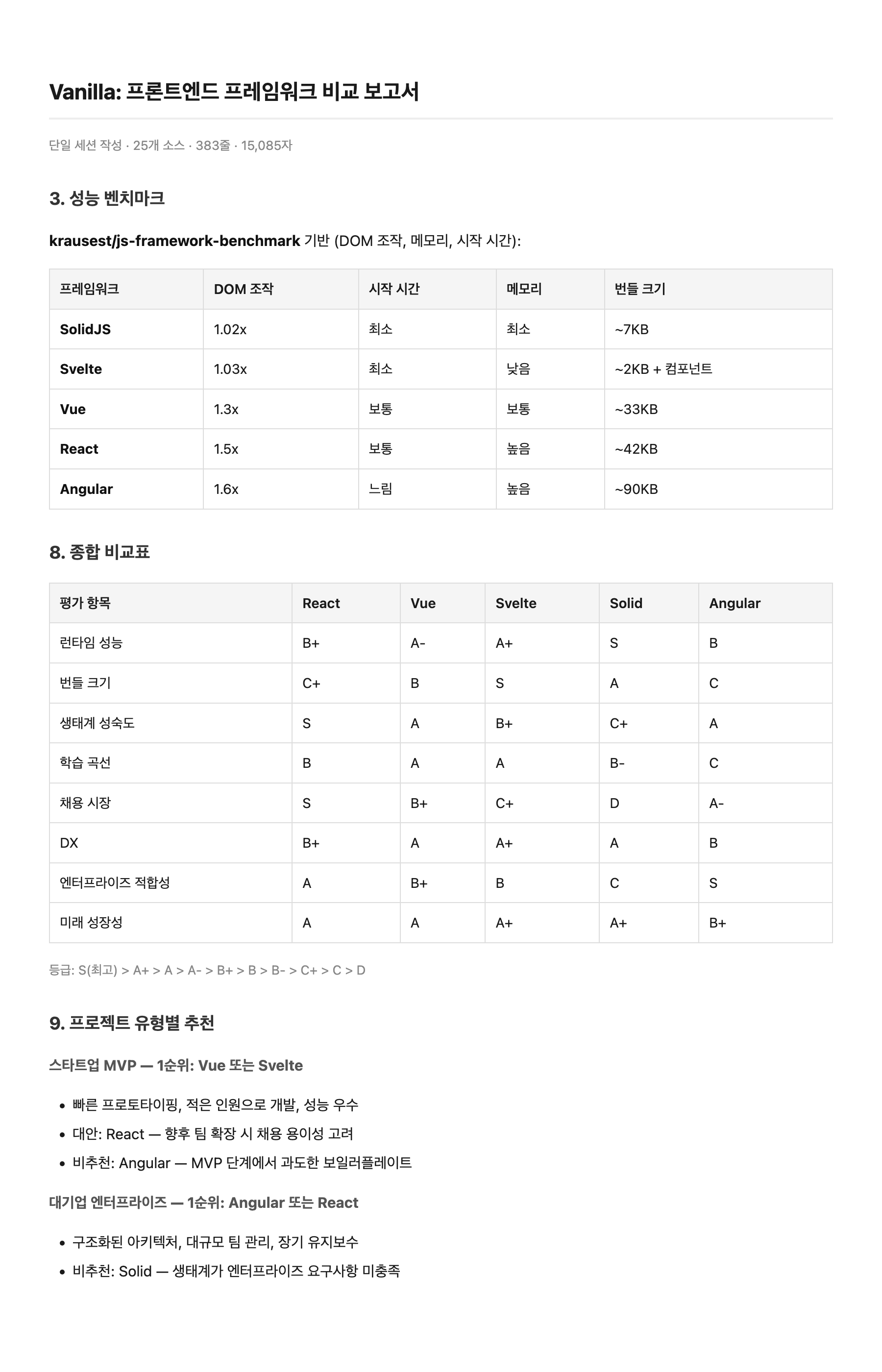
페이지 1 — 벤치마크 & 종합 비교표:
Vanilla
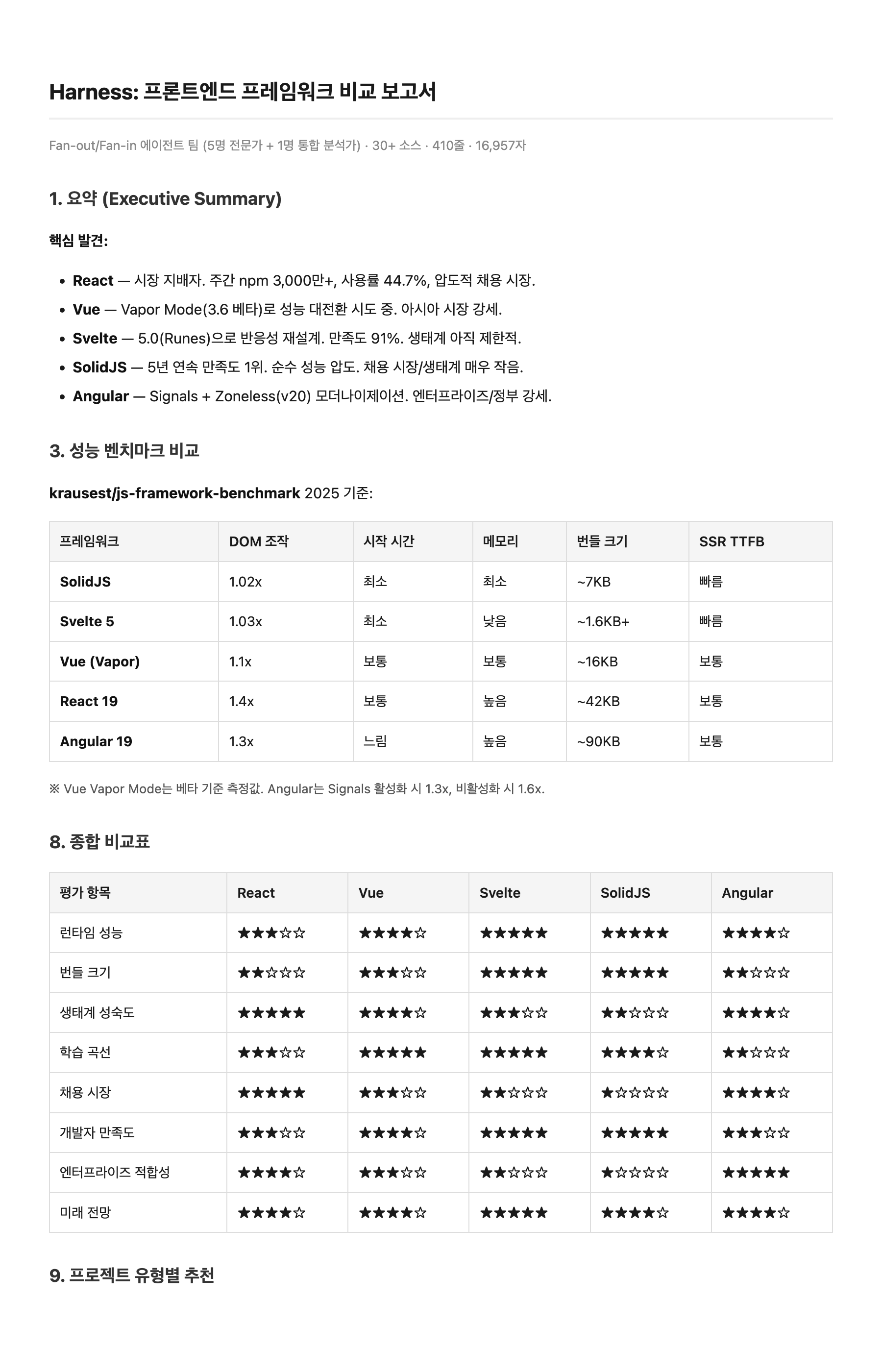
Harness
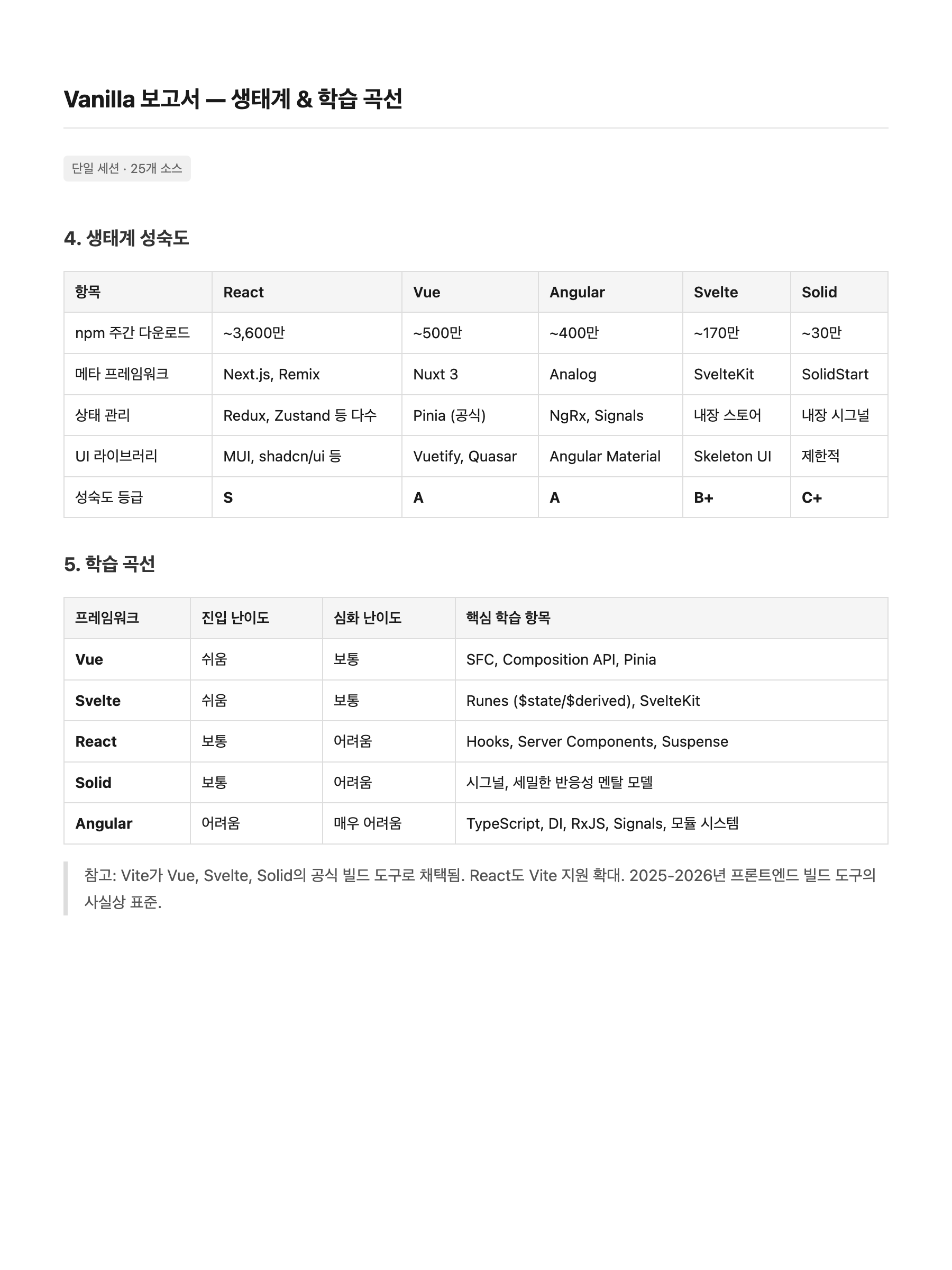
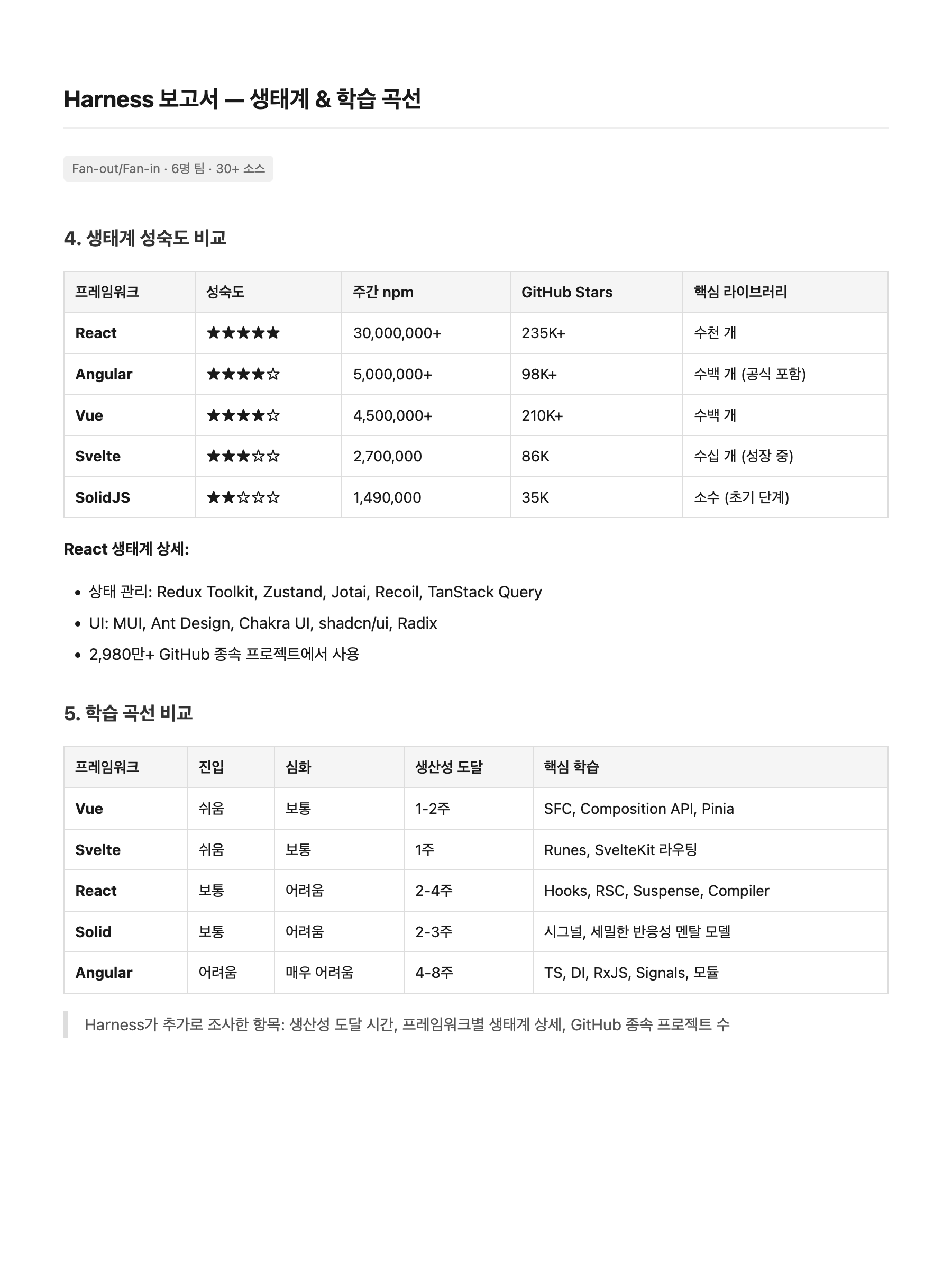
페이지 2 — 생태계 & 학습 곡선:
Vanilla
Harness
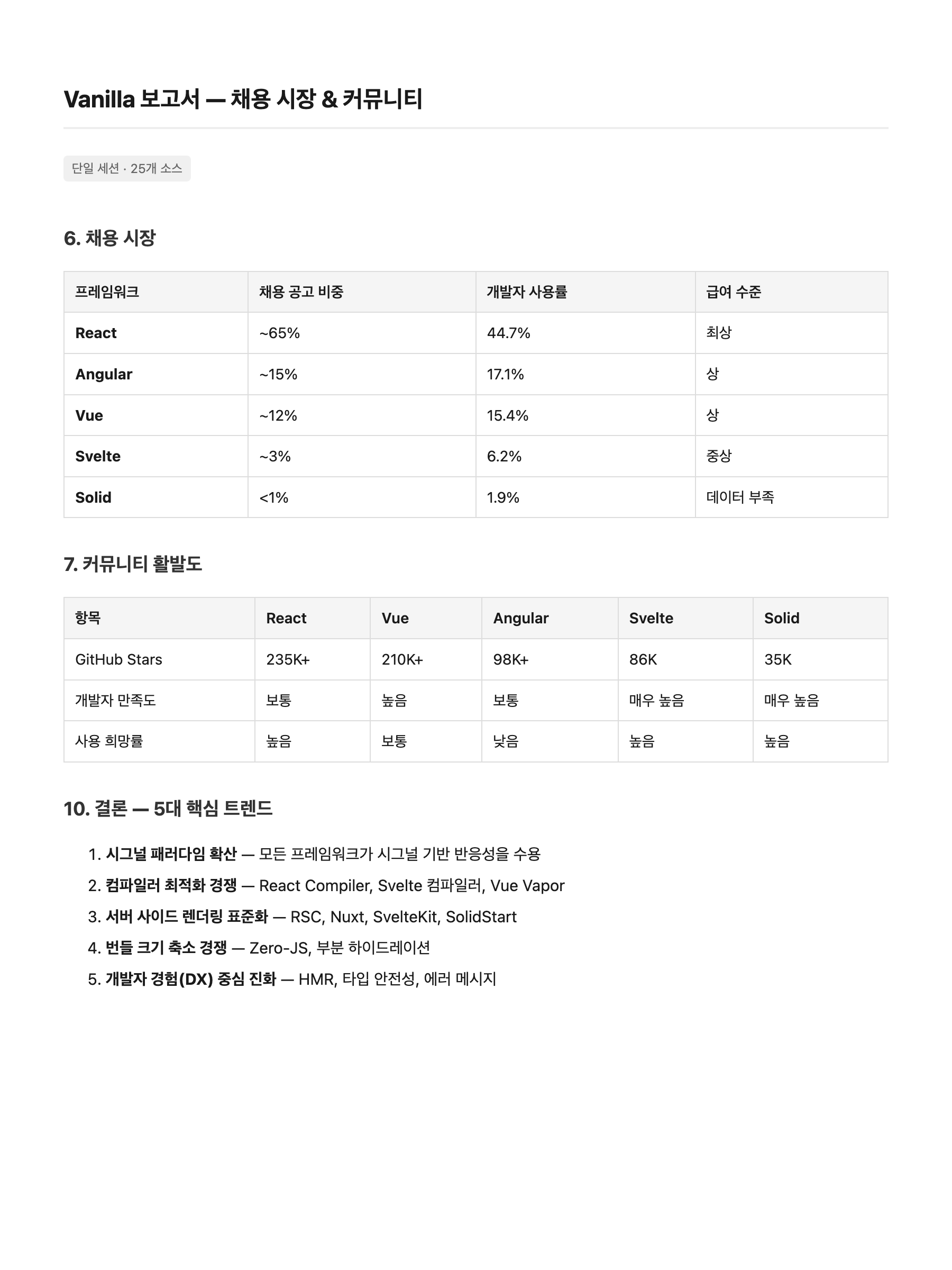
페이지 3 — 채용 시장 & 결론:
Vanilla
Harness
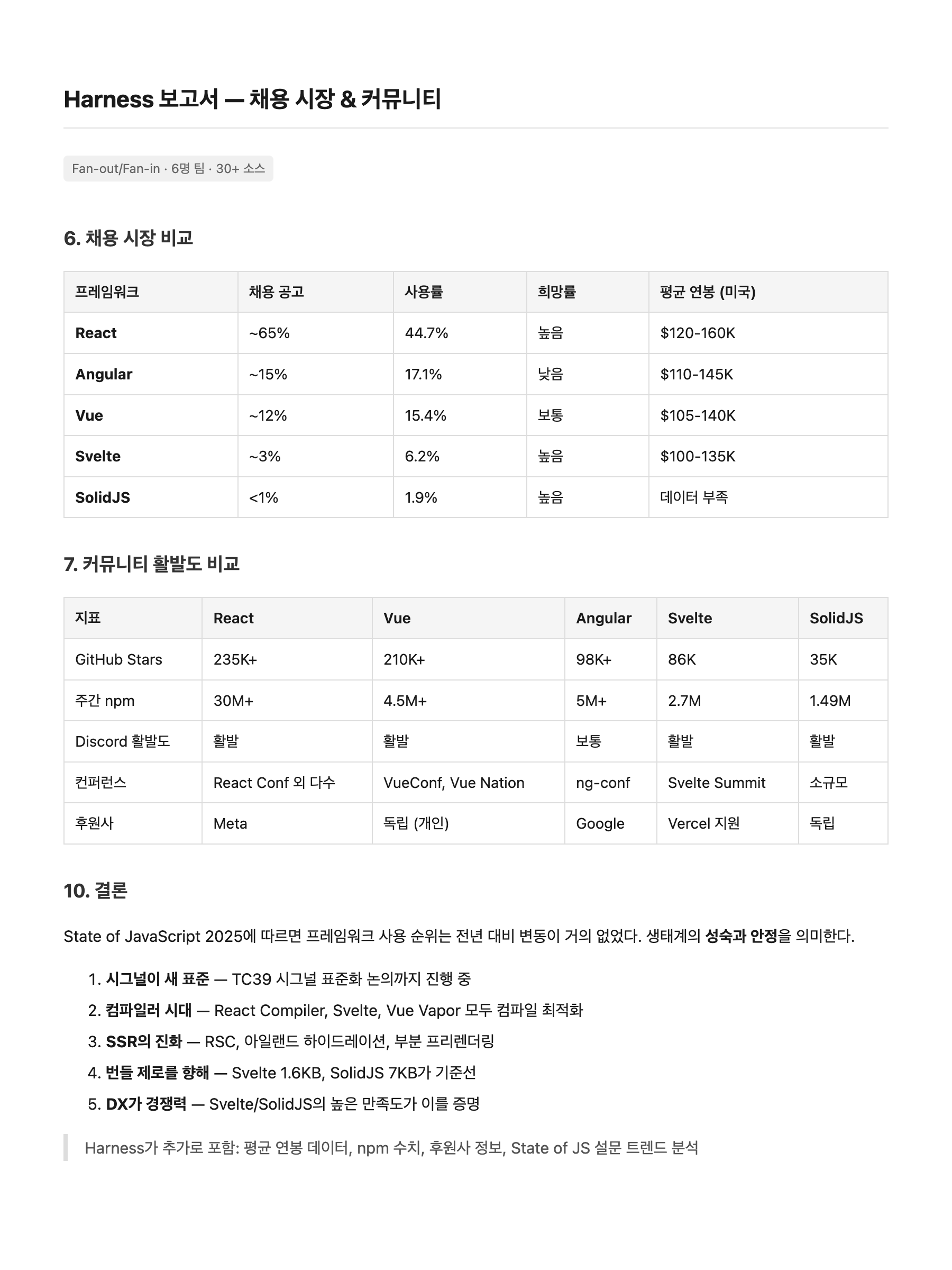
Harness 쪽이 컬럼이 1-2개 더 많고(SSR TTFB, 생산성 도달 시간, 연봉 데이터) 수치가 더 구체적이다. 하지만 분량은 비슷하지만 질적 차이가 뚜렷하다. Harness는 Executive Summary로 핵심 발견을 먼저 제시하고, 벤치마크 테이블에 SSR TTFB·FCP 컬럼을 추가했으며, npm 다운로드·GitHub Stars 같은 정확한 수치를 포함한다. "얼마나 썼느냐"가 아니라 "얼마나 구체적이냐"에서 차이가 난다.
시나리오 3: 코드 리뷰 (Fan-out/Fan-in)
프롬프트: 시나리오 1의 Vanilla가 만든 Todo 앱(1,138줄)에 대한 종합 코드 리뷰.
구성된 하네스: Fan-out/Fan-in (병렬 리뷰 → 통합)
├── security-reviewer — OWASP Top 10 기반 보안 감사
├── performance-reviewer — 렌더링, 메모리, 이벤트 처리
├── accessibility-reviewer — WCAG 2.1 AA 적합성 검사
├── architecture-reviewer — 구조, 패턴, 유지보수성
└── integration-reporter — 4개 리뷰 교차 분석 → 통합 리포트결과 비교
| 항목 | Vanilla | Harness |
|---|---|---|
| 발견 이슈 수 | 19개 | 50개 |
| ┗ Critical | 4 | 6 |
| ┗ Major | 6 | 20 |
| ┗ Minor | 9 | 24 |
| 소요 시간 | 1.8분 | ~2.8분 (병렬) |
| 교차 검증 | 0 | 7건 |
| 접근성 이슈 | 4개 | 20개 |
결과 분석
접근성 5배 차이 — Vanilla는 4개, Harness는 20개. lang="ko" 설정 오류, 포커스 인디케이터 제거, 모달 포커스 트랩 부재 등 Vanilla가 전혀 언급하지 않은 이슈들.
교차 검증 7건 — 여러 전문가가 같은 이슈를 다른 관점에서 독립적으로 발견.
직접 보기: 같은 보안 이슈를 다르게 분석
두 리뷰 모두 cat.color의 CSS 인젝션 문제를 잡았다. 하지만 깊이가 다르다.
Vanilla — 단일 세션
Critical로 분류
cat.color가 raw로 주입됨. 조작된 color 값으로 속성 주입 가능.
추천: hex color regex 검증 또는 element.style로 적용
Harness — 보안 전문가
더 정교한 위협 모델링
색상 피커가 UI에서 #rrggbb를 강제하지만, 저장된 값은 로드 시 검증 없음. 공유 오리진에서 localStorage를 조작하면 UI 리드레싱, 피싱 오버레이, url() 경유 데이터 유출 가능.
Harness — 아키텍처 전문가
같은 이슈를 다른 각도에서
innerHTML에 검증 없는 보간은 코드 품질 문제. 색상뿐 아니라 다른 사용자 데이터도 같은 패턴으로 주입될 수 있는 구조적 취약점.
왼쪽은 "이거 위험해요, 고치세요". 오른쪽은 공격 시나리오 + 구조적 원인까지 파고든다. 그리고 두 명의 전문가가 독립적으로 같은 이슈를 잡았다 — 이것이 교차 검증의 실제 가치다.
시나리오 4: 유틸리티 라이브러리 (Producer-Reviewer)
프롬프트: "JavaScript 유틸리티 라이브러리 — 배열(chunk, flatten, unique, groupBy, zip), 문자열(camelCase, kebabCase, truncate, slugify), 객체(deepClone, pick, omit, merge), 날짜(formatDate, timeAgo, isWeekend). 테스트까지."
구성된 하네스: Producer-Reviewer (생성 → 검증 반복)
├── producer — 라이브러리 코드 생성
└── reviewer — 독립적으로 테스트 작성 + 실행 + 버그 리포트결과 비교
| 항목 | Vanilla | Harness |
|---|---|---|
| 함수 수 | 16개 | 16개 |
| 테스트 수 | 95개 | 183개 |
| 통과율 | 100% | 100% |
| 발견 버그 | 1건 (slugify) | 0건 + 5개 설계 관찰 |
직접 보기: 같은 함수를 테스트하는 방식이 다르다
pick 함수에 대해 각각이 작성한 테스트를 비교해보자:
Vanilla — 5개 테스트
pick({a:1,b:2,c:3}, ['a','c']) → {a:1,c:3}
pick({a:1}, ['b']) → {}
pick({a:1,b:2}, []) → {}
pick(null, ['a']) → throws
pick({a:1}, 'a') → throws기본 동작 + 에러 케이스. 충분해 보인다.
Harness Reviewer — 8개 테스트
pick({a:1,b:2,c:3}, ['a','c']) → {a:1,c:3}
pick({a:1,b:2}, []) → {}
pick({a:1,b:2}, ['x']) → {}
pick({a:undefined}, ['a']) → {a:undefined}
pick({}, ['a']) → {}
pick(null, ['a']) → throws
pick('str', ['a']) → throws
pick({a:1}, 'a') → throws
// + 상속 속성 테스트:
pick(protoObj, ['inherited']) → {inherited:'yes'}undefined 값, 빈 객체, 상속 속성까지 커버.
그리고 Reviewer는 Vanilla가 절대 발견할 수 없는 것을 하나 찾아냈다:
설계 관찰 #3:pick은in연산자를 사용해서 상속 속성을 포함하지만,omit은Object.keys()를 사용해서 자기 속성만 처리한다. 같은 라이브러리의 두 함수가 상속 속성을 다르게 취급하는 비대칭이 있다.
버그는 아니지만, 만든 사람이 알아채기는 어려운 종류의 문제다.
시나리오 5: 프로덕션 인시던트 진단 (Expert Pool)
프롬프트: "새벽 3시에 프로덕션 에러율이 급증했다. 원인을 모른다. 이 로그를 분석하여 근본 원인을 찾고 해결 방안을 제시하라." — DB 타임아웃, 메모리 급증, 인증 실패, API 응답 지연 등 여러 도메인의 증상이 섞인 로그 제공.
구성된 하네스: Expert Pool (증상 분류 → 전문가 선택 호출)
├── triage (먼저 로그를 읽고 증상 유형 분류)
├── db-expert — 쿼리 타임아웃, 데드락, 커넥션 풀, 슬로우 쿼리
├── infra-expert — 메모리, GC, 캐시, 레이트 리밋
├── security-expert — 인증 실패, 웹훅 서명, JWT 문제
└── app-expert — 코드 버그, 비즈니스 로직, API 에러
(증상 분류 결과에 따라 4명 모두 호출됨)결과 비교
| 항목 | Vanilla | Harness |
|---|---|---|
| 식별 이슈 | 11개 | 14개 |
| 근본 원인 | v2.15.0 배포 | v2.15.0 배포 (동일) |
| 인과 관계 | 8개 | 8개 |
| 토큰 | 16,104 | 36,588 |
직접 보기: 인과 관계 분석 비교
Vanilla — 인과 체인
1. JWT 교체 → 세션 무효화 → 재로그인 폭증
2. bulk 엔드포인트 → 847개 IN절 → PG 타임아웃
3. PG 타임아웃 → 커넥션 풀 고갈 → Sequelize 타임아웃
4. 커넥션 풀 고갈 → 메모리 누수 → GC pause → 악순환
11개 이슈, 8개 인과 관계
Harness — 인과 체인
1. JWT 교체 → auth 실패 → retry storm → rate limit 초과
2. bulk 엔드포인트 → 847개 쿼리 → PG 타임아웃 → 풀 고갈
3. JWT 교체 → Stripe 웹훅 서명도 실패
4. Event listener 누수 → 메모리 → GC → 응답 지연
5. Redis 고갈 → 키 퇴거 → CDN 캐시 미스 연쇄
14개 이슈, 8개 인과 관계
근본 원인(v2.15.0 배포)과 인과 관계 수(8개)는 동일하다. 하지만 Harness가 3개 이슈를 더 찾았고, 인과 체인이 더 구체적이다 — "auth 실패"에서 끝나지 않고 "retry storm → rate limit 초과"까지 추적하고, JWT 교체가 Stripe 웹훅에도 영향을 준다는 도메인 간 연쇄를 짚어냈다. 각 전문가가 자기 도메인에서 깊이 파고든 뒤 결과를 합치면, 단일 세션이 놓치는 교차 영향을 발견할 수 있다.
시나리오 6: 콘텐츠 기획 (Supervisor)
프롬프트: "기술 블로그 콘텐츠 기획서 — 'WebAssembly가 프론트엔드를 바꾸는 5가지 방법'. SEO, 경쟁 분석, 아웃라인, 소셜 전략, 썸네일."
구성된 하네스: Supervisor (중앙 조율 + 동적 분배)
├── supervisor — 총괄: 작업 분배, 결과 통합
├── seo-researcher — 키워드 리서치, SEO 전략
├── competitor-analyst — 상위 5개 검색 결과 분석
├── content-writer — 글 아웃라인, 썸네일 콘셉트
└── social-strategist — Twitter/LinkedIn/HN 배포 전략결과 비교
| 항목 | Vanilla | Harness |
|---|---|---|
| 기획서 길이 | 11,519자 / 401줄 | 7,284자 / 246줄 |
| 경쟁 분석 | 5개 (일반 지식) | 5개 (실제 웹 검색 + URL) |
| 소셜 전략 | 4채널 전략 서술 | 4채널 + 실제 트윗 7개 초안 |
실제 결과물: 소셜 배포 전략 비교
Vanilla

Harness

Vanilla는 트윗 옵션 3개와 LinkedIn 포스트 1개를 제시했다. Harness는 바로 복사해서 쓸 수 있는 7개 트윗 스레드 전문 + LinkedIn + HN 제목 3개를 만들었다. 전략 서술 vs 실제 초안 — Supervisor 패턴에서 각 전문가가 자기 영역의 최종 산출물까지 만들어내는 차이가 여기서 드러난다.
종합 비교
| 패턴 | 시나리오 | 핵심 지표 | Vanilla | Harness | 승자 |
|---|---|---|---|---|---|
| Pipeline | 웹앱 | 코드 라인 | 1,138 | 1,480 | 무승부 |
| Fan-out | 리서치 | 참고 소스 | 25 | 30+ | Harness 우세 |
| Fan-out | 코드 리뷰 | 이슈 발견 | 19 | 50 | Harness 압승 |
| Producer-Reviewer | 라이브러리 | 테스트 수 | 95 | 183 | Harness 우세 |
| Expert Pool | 인시던트 진단 | 이슈 발견 | 11 | 14 | Harness 우세 |
| Supervisor | 콘텐츠 기획 | 구체성 | 분량 많음 | 실행력 높음 | 관점 차이 |
6개 실험에서 보이는 패턴
Harness가 확실히 유리한 작업:
- 코드 리뷰 (Fan-out) — 이슈 2.6배, 접근성 5배. 전문가 분리의 가치가 가장 극적
- 테스트/검증 (Producer-Reviewer) — 테스트 수 2배. 만든 사람과 검증하는 사람이 분리되면 품질이 올라감
- 리서치 (Fan-out) — 분량은 비슷하지만 구체성이 다름. 정확한 수치, 추가 분석 컬럼, Executive Summary 등 보고서 품질이 높아짐
- 인시던트 진단 (Expert Pool) — 이슈 14개 vs 11개. 도메인 간 연쇄(JWT→Stripe, Redis→CDN)를 전문가 분리로 추가 발견
차이가 미미하거나 Vanilla이 나은 작업:
- 단순 구현 (Pipeline) — 토큰 3.4배 비용을 정당화하기 어려움
- 콘텐츠 기획 (Supervisor) — 분량은 Vanilla이 많지만 Harness가 실행 가능한 구체성에서 앞섬. 관점 차이
핵심 규칙: "한 명이 넓게 보는 것"보다 "여러 명이 깊이 보는 것"이 중요한 작업에서 Harness가 빛난다. 반대로, 코드를 위에서 아래로 읽으면 답이 보이는 작업에서는 굳이 팀을 나눌 필요가 없다.
결론
Harness의 주장은 맞는가?
실험 설계에서 "자기 맹점이 있는가?"를 물었다. 있다. 시나리오 3에서 Vanilla는 접근성을 4개만 찾았지만 Harness는 20개를 찾았고, 시나리오 4에서 Vanilla는 pick/omit의 설계 비대칭을 놓쳤다. 만든 사람이 검증도 하면 같은 사고 과정을 반복하게 되고, 같은 맹점이 반복된다.
부분적으로 맞다. 모든 작업에서 60% 향상되는 건 아니다. 하지만 전문성이 깊이를 요구하는 작업에서는 확실한 차이를 만든다.
6개 실험 중 Harness가 확실히 이긴 건 코드 리뷰, 라이브러리 테스트, 인시던트 진단, 리서치. 웹앱은 비겼고, 콘텐츠 기획은 관점이 달랐다. 만능은 아니다.
나에게 맞는 하네스를 찾는 법
아래 질문을 자신에게 해보자:
1. 이 작업에 전문 관점이 몇 개 필요한가?
보안, 성능, 접근성처럼 2개 이상의 독립된 전문성이 필요하면 Harness가 확실히 낫다. 이 실험에서 가장 큰 차이가 난 건 전부 이 경우였다.
2. 만든 사람과 검증하는 사람이 분리되어야 하는가?
자기가 만든 코드를 자기가 테스트하면 맹점이 생긴다. 테스트, QA, 코드 리뷰처럼 생성과 검증이 분리되면 좋은 작업이면 Producer-Reviewer가 효과적이다.
3. 이 유형의 작업을 앞으로 반복할 건가?
하네스를 만드는 데 드는 초기 비용이 있다. 한 번 쓰고 말 거면 Vanilla이 빠르다. 하지만 같은 유형의 작업을 주기적으로 한다면 — 매주 코드 리뷰, 매달 보안 감사, 분기별 리서치 — 하네스를 만들어두면 매번 재사용할 수 있다.
4. 여러 도메인에 걸친 문제인가?
프로덕션 인시던트처럼 DB, 인프라, 보안, 앱 로직이 복합적으로 얽힌 문제는 Expert Pool로 각 전문가가 자기 도메인을 깊이 파고든 뒤 합치는 게 효과적이다.
반대로, 코드를 위에서 아래로 읽으면 답이 보이는 작업, 단일 관점으로 충분한 작업에서는 굳이 팀을 나눌 필요가 없다.
진짜 깨달음: 하네스는 하나가 아니라 여러 개 만드는 것
이 실험을 하면서 깨달은 건, 하네스 하나를 잘 만들 게 아니라 여러 개를 만들면 된다는 것이다.
코드 리뷰할 때는 코드 리뷰 하네스. 웹앱 만들 때는 웹앱 하네스. 보안 감사할 때는 보안 하네스. 마치 프로젝트마다 팀을 새로 꾸리듯이. 그래서 이름이 "메타 스킬"이고, harness-100이 100개를 미리 만들어둔 것이다.
이렇게 생각하면 시나리오별 ROI가 명확해진다:
- 코드 리뷰 → 전용 하네스 구축 → 매번 재사용 → 투자 대비 효과 극대화
- 리서치 → 하네스를 쓰면 구체성이 올라감 → 반복 리서치라면 하네스 구축 가치 있음
- 보안 감사 → 보안 전용 하네스 → OWASP 체크리스트 내장 → 매번 재사용
"이 작업에 하네스를 쓸까 말까"가 아니라, "이 유형의 작업을 앞으로 반복할 건가"가 진짜 질문이다. 반복할 작업이라면 하네스를 만들어두는 게 맞고, 일회성이면 Vanilla이 낫다.
프롬프트를 다듬는 것보다 구조를 바꾸는 것이 더 효과적일 수 있다 — 단, 그 구조를 반복해서 쓸 수 있을 때.
Harness는 Apache 2.0 라이선스로 공개되어 있으며, 상업적 사용이 자유롭다.
시작하기
# 설치
git clone https://github.com/revfactory/harness.git
cp -r harness/skills/harness ~/.claude/skills/harness
# 사용 — 아무 프로젝트에서
"이 프로젝트를 위한 harness를 구축해줘"
# 이미 만들어진 100개 팀 중 골라 쓰기
git clone https://github.com/revfactory/harness-100.git
cp -r harness-100/ko/30-code-review/.claude/ ./my-project/.claude/- Harness GitHub: revfactory/harness
- 100개 에이전트 팀 컬렉션: revfactory/harness-100

Member discussion: